技术详情
Barcode长度和barcode文库复杂度
使用核苷酸创建barcode 涉及为不同的信息分配独特的DNA序列。首先,可以使用一个短的核苷酸序列编码基础信息,例如一个特定细胞的标识符。具体而言,“ATCG”可能代表细胞1,“TAGC”代表细胞2。随着barcode长度的增加,编码信息的复杂性和多样性会呈指数级增长。Barcode的长度越长,可用的排列组合数量越多,其识别更多变体的能力也越强。
Barcode 文库的最大复杂度可以根据给定的一组核苷酸其生成的排列组合数目计算。对于随机核苷酸的barcode ,每个位置可能有四种结果:A、T、G或C。给定barcode长度(N)的排列组合总数(复杂度)为4N。例如:一个随机NNN barcode 有64种(43)可能的组合。随着barcode长度的增加,复杂度呈指数级增长。这种指数增长彰显了barcode文库可使用更长的序列来编码信息的能力,因为它允许barcode中拥有数量众多的唯一标识符。
载体和barcode设计
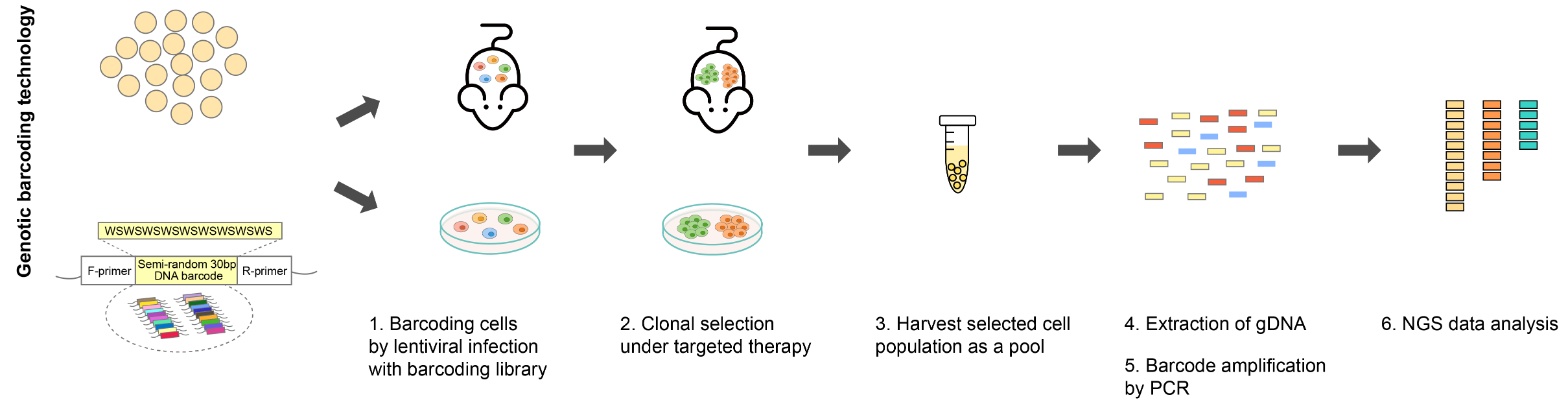
设计病毒载体中barcode的位置需要策略性的考量,以确保读取计数的有效性以及与文库克隆、筛选和去卷积分析过程的兼容性。对于慢病毒载体,barcode应位于到病毒载体的整合区域中,确保它与相关遗传元件(如gRNA或可变区域)一起稳定整合到宿主基因组中。如果将barcode定位在转录区域内,将可通过RNA转录物进行barcode读取。为了方便后续分析,所选barcode序列应兼容PCR,以便有效且均匀地扩增。此外,barcode设计应适用于NGS,确保在测序过程中可检测和准确量化。理想情况下,barcode序列不应干扰所研究的生物过程,以避免结果出现人工假象,但这通常要求充备的先验知识以进行判断。
设计barcode还需要考虑所谓一对一或多对一策略。Barcode和可变区之间的一对一关系意味着单个barcode仅代表一个可变区,这确保了barcode与其各自的可变区之间直接关联。而在多对一关系中,多个barcode可以代表相同的可变区。这种策略具有特别的优势:首先,将表示相同可变区的多个barcode视为重复样本,从而增强了阳性结果的可统计性。这种统计数据量的提升有利于识别真正的阳性结果并将其与高通量实验中产生的随机变化相区分。其次,为同一可变区使用多个barcode可以进行克隆分析,这对于研究异质性细胞群(如肿瘤细胞)也有重要的价值。
Barcode基因递送和NGS分析
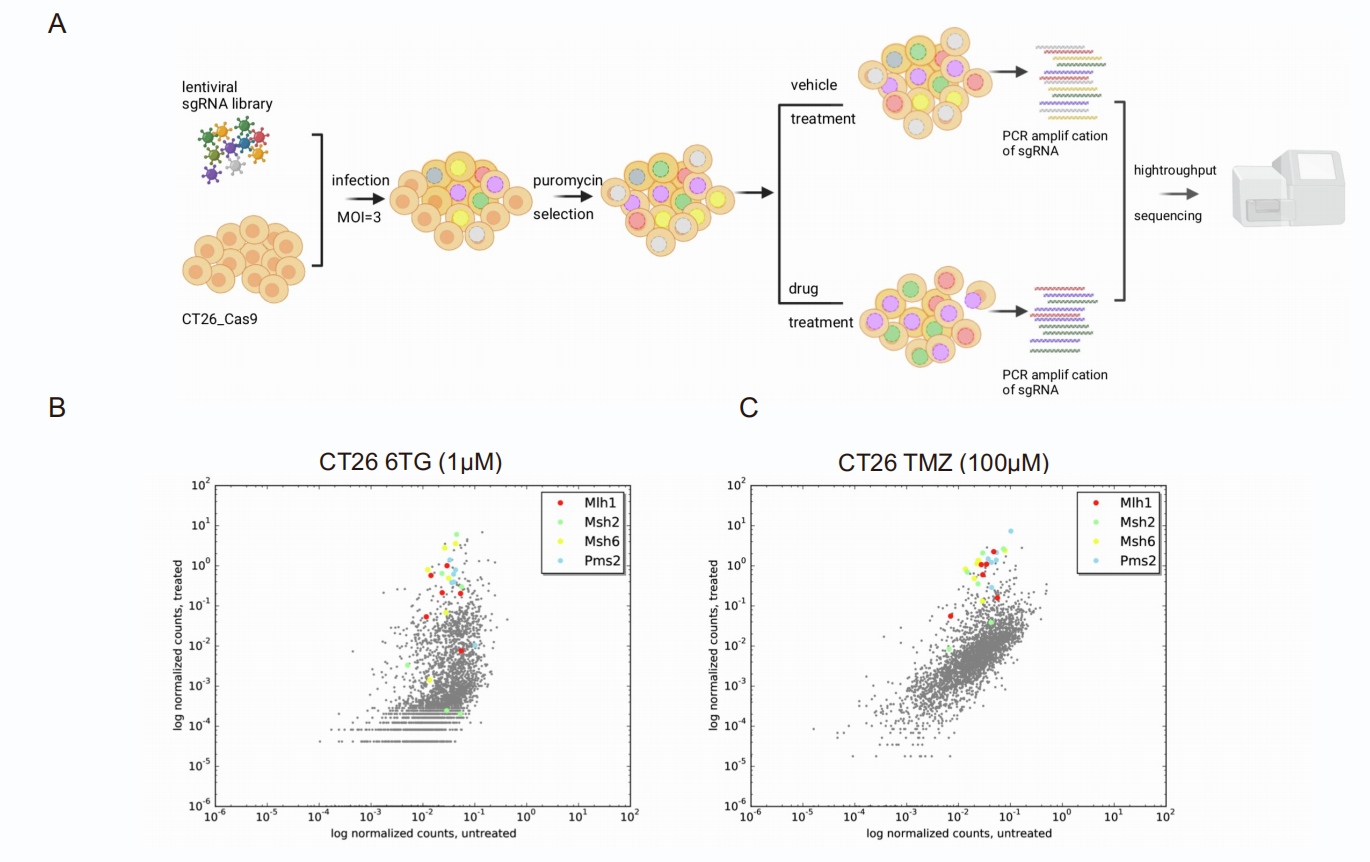
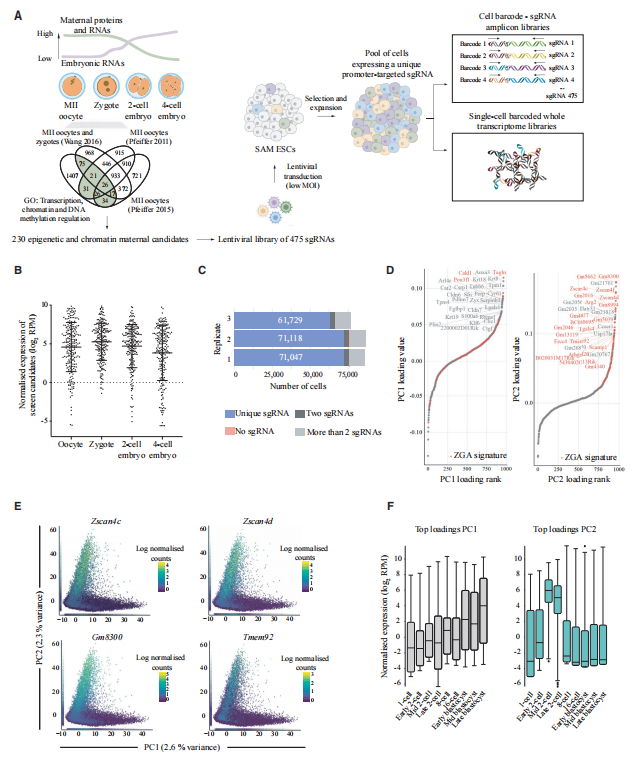
为了将DNA barcode递送到细胞中,研究人员可以使用病毒载体如慢病毒、AAV和逆转录病毒系统,或者非病毒载体如piggyBac和Sleeping Beauty的转座子系统。特别是在NGS分析时,分离细胞的barcode需要确定使用RNA还是基因组DNA用作barcode读取,而这是由将barcode引入细胞的基因递送系统类型决定的。将barcode永久性地整合到细胞基因组中的系统有利于基因组DNA的分离。然而,这还需要确保它们适合于PCR扩增并与NGS测序兼容。另一方面,如果barcode作为转录本的一部分表达,RNA则反映了barcode的读取信号。在单细胞RNA测序实验中,如Perturb-Seq和CROP-Seq,需要同时捕获转录本和barcode信息,RNA读取对于实验设计的兼容性至关重要。总而言之,barcode读取策略的选择与barcode递送系统的既定特征以及实验目标是密切关联的,而这也印证了高度定制化的实验方法对于相对独特的研究的重要性。
实验数据
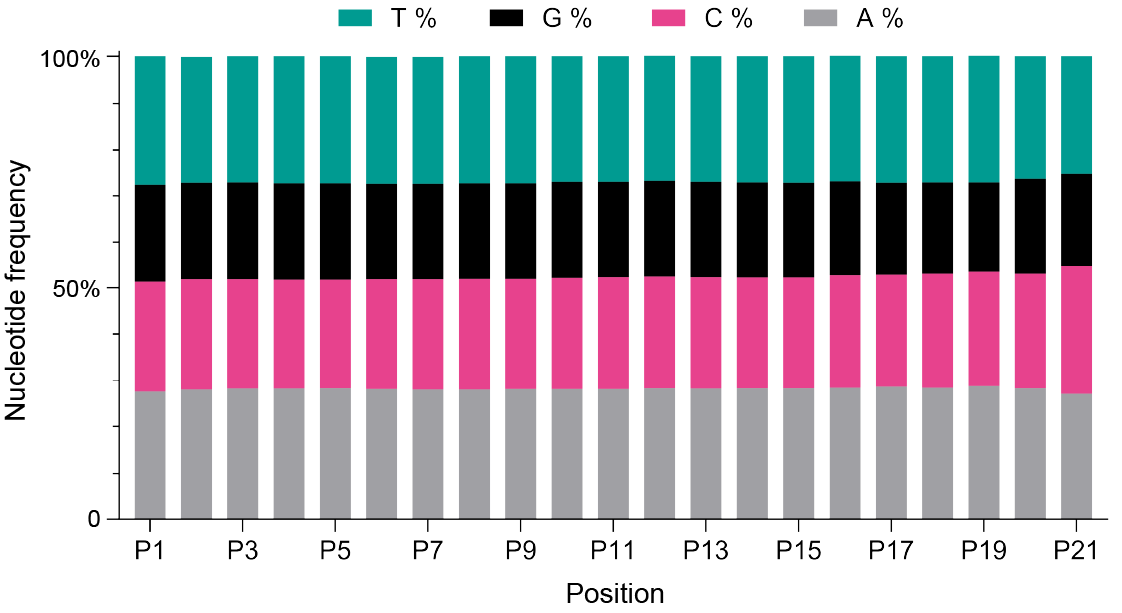
图1 一个N(21)barcode的核苷酸分布,使用简并核苷酸策略显示每个位置的A、C、G、T的百分比。该图表明在所有位置的核苷酸比例分布相近。